Measures of Center
Suppose we have observations `y_1, ..., y_n`
mean: `bar(y) = (y_1 + ... + y_n)/n = 1/n sum_(i = 1)^n y_i`
median:
- arrange numbers in increasing order
- if `n` is odd, the median is the observation in center
- if `n` is even, the median is the mean of the two observations in the center
Ex: `2, 4, 5, 9`
mean = `(2 + 4 + 5 + 9)/4 = 5`
median = `(4 + 5)/2 = 4.5`
Measures of Variation
Ex: `8, 10, 12`
`bar(y) = 10`
`s = sqrt(((8-10)^2 + (10-10)^2 + (12-10)^2)/(3-1)) = 2`
interquartile range (IQR):
- arrange data in increasing order
- lower quartile `Q_1` is the median of the observations to the left of the median
- upper quartile `Q_3` is the median of the observations to the right of the median
- IQR = `Q_3 - Q_1`
Ex: 1, 2, 3, 4, 5, 6, 7
median = `4`
`Q_1 = 2.5`
`Q_3 = 5.5`
`IQR = 3`
Note: standard deviation is sensitive to outliers. IQR is not.
Use the mean and standard deviation if the data is symmetric and there are no outliers
Use the median and IQR if the data is skewed and there are outliers
Relative Standing
Suppose we have observations `y_1, ..., y_n`
z-score: number of standard deviations away from the mean
To find the z-score associated with a given `y_i`, subtract the mean of the observations and divide by the standard deviation
`z = (y_i - bar(y))/s`
Ex: Comparing Sports Teams
|
W-L |
% |
Mean |
SD |
z-score |
| Patriots |
14-2 |
.875 |
.500 |
.200 |
1.88 |
| Cubs |
103-58 |
.640 |
.500 |
.062 |
2.26 |
z-score for Patriots: `(.875 - .500)/.200 ~~ 1.88`
z-score for Cubs: `(.640 - .500)/.062 ~~ 2.26`
The Patriots have a higher win %, but the Cubs have a higher z-score. This means that the Cubs getting a win is more impressive.
Linear Regression
Goal: predict the value of a variable `y` (response variable) given the value of a variable `x` (explanatory variable)
Fit a line to the data and use the line to predict `y` from `x`
Equation of the line is `hat(y) = b_0 + b_1x` where `b_0` is the intercept and `b_1` is the slope
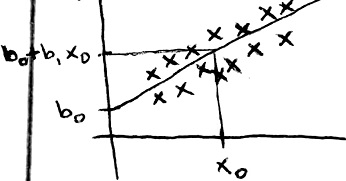
If the value of the explanatory variable is `x_0` then the prediction for the response variable is `b_0 + b_1x_0`
For each point, the vertical distance `y-hat(y)` between the point and the line is called the prediction error or residual
least squares regression line: the line that minimizes the sum of squares of residuals
Let `bar(x)` and `bar(y)` be the means of two variables
Let `s_x` and `s_y` be the standard deviations
Let `r` be the correlation
The least squares regression line is `hat(y) = b_0 + b_1x` where `b_1 = (rs_y)/s_x` and `b_0 = bar(y) - b_1bar(x)`
Ex: Let `x` be the father's height and `y` be the son's height
Let `bar(x) = 67.7`, `bar(y) = 68.7`, `s_x = 2.72`, `s_y = 2.82`, `r = 0.50`
Then `b_1 = (0.5)(2.82/2.72) ~~ 0.518` and `b_0 = 68.7 - (0.518)(67.7) ~~ 33.6`
So the least squares regression line is `hat(y) = 33.6 + 0.518x`
If the father's height is `74` inches (`x = 74`), then we predict the son's height is `33.6 + 0.518(74) ~~ 71.9` inches
Every additional inch of the father's height increases the predicted son's height by `0.518` inches
The intercept (`b_0`) often has little statistical meaning
If the regression line goes through `(bar(x), bar(y))`, then if `x` is the average, then `y` is also the average
If `x = bar(x)+s_x`, then `hat(y) = b_0 + b_1(bar(x)+s_x) = b_0 + b_1bar(x) + b_1s_x = hat(y) + rs_y`
In words, if `x` is one standard deviation above the mean, we predict `y` to be `r` standard deviations above the mean
Because `-1 <= r <= 1`, this leads to the "regression effect"